![]()
Databricks-Certified-Professional-Data-Scientist Actual Questions Answers Pass With Real Databricks-Certified-Professional-Data-Scientist Exam Dumps
Databricks-Certified-Professional-Data-Scientist Dumps Prepare Your Exam With 140 Questions
Databricks Databricks-Certified-Professional-Data-Scientist Exam Syllabus Topics:
| Topic | Details |
|---|---|
| Topic 1 |
|
| Topic 2 |
|
| Topic 3 |
|
NEW QUESTION 66
Refer to Exhibit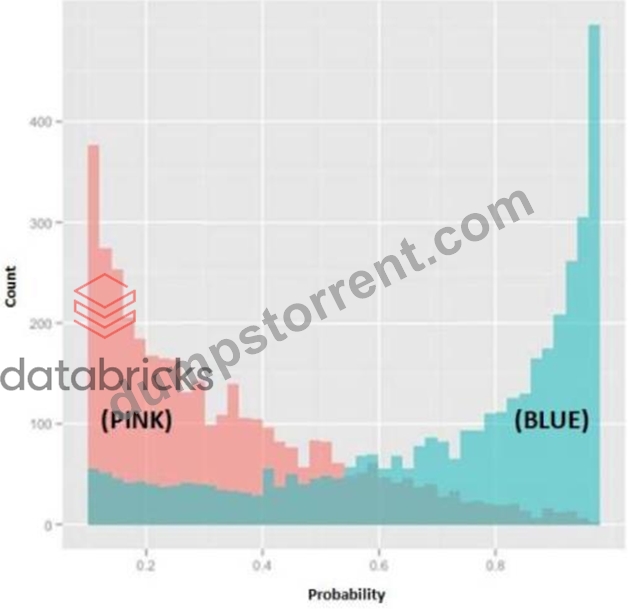
In the exhibit, the x-axis represents the derived probability of a borrower defaulting on a loan. Also in the exhibit, the pink represents borrowers that are known to have not defaulted on their loan, and the blue represents borrowers that are known to have defaulted on their loan. Which analytical method could produce the probabilities needed to build this exhibit?
- A. Linear Regression
- B. Association Rules
- C. Discriminant Analysis
- D. Logistic Regression
Answer: D
NEW QUESTION 67
In which lifecycle stage are test and training data sets created?
- A. Model planning
- B. Discovery
- C. Model building
- D. Data preparation
Answer: C
Explanation:
Explanation
In Phase 1, the team learns the business domain, including relevant history such as whether the organization or business unit has attempted similar projects in the past from which they can learn. The team assesses the resources available to support the project in terms of people, technology time, and data. Important activities in this phase include framing the business problem as an analytics challenge that can be addressed in subsequent phases and formulating initial hypotheses (IHs) to test and begin learning the data. Data preparation: Phase 2 requires the presence of an analytic sandbox, in which the team can work with data and perform analytics for the duration of the project. The team needs to execute extract, load, and transform (ELT) or extract, transform and load (ETL) to get data into the sandbox. The ELT and ETL are sometimes abbreviated as ETLT Data should be transformed in the ETLT process so the team can work with it and analyze it. In this phase, the team also needs to familiarize itself with the data thoroughly and take steps to condition the data Model planning:
Phase 3 is model planning, where the team determines the methods, techniques, and workflow it intends to follow for the subsequent model building phase. The team explores the data to learn about the relationships between variables and subsequently selects key variables and the most suitable models.
Model building: In Phase 4, the team develops datasets for testing, training, and production purposes. In addition, in this phase the team builds and executes models based on the work done in the model planning phase. The team also considers whether its existing tools will suffice for running the models, or if it will need a more robust environment for executing models and workflows (for example, fast hardware and parallel processing, if applicable).
Communicate results: In Phase 5, the team, in collaboration with major stakeholders, determines if the results of the project are a success or a failure based on the criteria developed in Phase 1. The team should identify key findings, quantify the business value, and develop a narrative to summarize and convey findings to stakeholders.
Operationalize: In Phase 6, the team delivers final reports, briefings, code, and technical documents. In addition, the team may run a pilot project to implement the models in a production environment.
NEW QUESTION 68
The method based on principal component analysis (PCA) evaluates the features according to
- A. The projection of the largest eigenvector of the correlation matrix on the initial dimensions
- B. None of the above
- C. According to the magnitude of the components of the discriminate vector
- D. The projection of the smallest eigenvector of the correlation matrix on the initial dimensions
Answer: A
Explanation:
Explanation
Feature Selection:
The method based on principal component analysis (PCA) evaluates the features according to the projection of the largest eigenvector of the correlation matrix on the initial dimensions, the method based on Fisher's linear discriminate analysis evaluates. Them according to the magnitude of the components of the discriminate vector.
NEW QUESTION 69
Which of the following statement is true for the R square value in the regression model?
- A. R square can be increased by adding more variables to the model.
- B. R-squared never decreases upon adding more independent variables.
- C. When R square =0, all the residual are equal to 1
- D. When R square =1 , all the residuals are equal to 0
Answer: A,B,D
Explanation:
Explanation
R square can be made high, it means when we add more variables R-square will increase. And R-square will never decreases if you add more independent variables. Higher R square value can have lower the residuals.
NEW QUESTION 70
Which of the following statement true with regards to Linear Regression Model?
- A. Ordinary Least Square is a sum of the squared individual distance between each point and the fitted line of regression model.
- B. In Linear model, it tries to find multiple lines which can approximate the relationship between the outcome and input variables.
- C. Ordinary Least Square can be used to estimates the parameters in linear model
- D. Ordinary Least Square is a sum of the individual distance between each point and the fitted line of regression model.
Answer: A,C
Explanation:
Explanation
Linear regression model are represented using the below equation
Where B(0) is intercept and B(1) is a slope. As B(0) and B(1) changes then fitted line also shifts accordingly on the plot. The purpose of the Ordinary Least Square method is to estimates these parameters B(0) and B(1).
And similarly it is a sum of squared distance between the observed point and the fitted line. Ordinary least squares (OLS) regression minimizes the sum of the squared residuals. A model fits the data well if the differences between the observed values and the model's predicted values are small and unbiased.
NEW QUESTION 71
You are analyzing data in order to build a classifier model. You discover non-linear data and discontinuities that will affect the model. Which analytical method would you recommend?
- A. Linear Regression
- B. Logistic Regression
- C. Decision Trees
- D. ARIMA
Answer: C
Explanation:
Explanation
A decision tree is a flowchart-like structure in which each internal node represents a "test" on an attribute (e.g.
whether a coin flip comes up heads or tails), each branch represents the outcome of the test and each leaf node represents a class label (decision taken after computing all attributes). The paths from root to leaf represents classification rules.
In decision analysis a decision tree and the closely related influence diagram are used as a visual and analytical decision support tool, where the expected values (or expected utility) of competing alternatives are calculated.
A decision tree consists of 3 types of nodes:
1. Decision nodes - commonly represented by squares
2. Chance nodes - represented by circles
3. End nodes - represented by triangles
Decision trees are commonly used in operations research, specifically in decision analysis, to help identify a strategy most likely to reach a goal. If in practice decisions have to be taken online with no recall under incomplete knowledge, a decision tree should be paralleled by a probability model as a best choice model or online selection model algorithm. Another use of decision trees is as a descriptive means for calculating conditional probabilities.
Decision trees, influence diagrams, utility functions, and other decision analysis tools and methods are taught to undergraduate students in schools of business, health economics, and public health, and are examples of operations research or management science methods.
NEW QUESTION 72
Question-3: In machine learning, feature hashing, also known as the hashing trick (by analogy to the kernel trick), is a fast and space-efficient way of vectorizing features (such as the words in a language), i.e., turning arbitrary features into indices in a vector or matrix. It works by applying a hash function to the features and using their hash values modulo the number of features as indices directly, rather than looking the indices up in an associative array. So what is the primary reason of the hashing trick for building classifiers?
- A. It requires the lesser memory to store the coefficients for the model
- B. It reduces the non-significant features e.g. punctuations
- C. Noisy features are removed
- D. It creates the smaller models
Answer: A
Explanation:
Explanation
This hashed feature approach has the distinct advantage of requiring less memory and one less pass through the training data, but it can make it much harder to reverse engineer vectors to determine which original feature mapped to a vector location. This is because multiple features may hash to the same location. With large vectors or with multiple locations per feature, this isn't a problem for accuracy but it can make it hard to understand what a classifier is doing.
Models always have a coefficient per feature, which are stored in memory during model building. The hashing trick collapses a high number of features to a small number which reduces the number of coefficients and thus memory requirements. Noisy features are not removed; they are combined with other features and so still have an impact.
The validity of this approach depends a lot on the nature of the features and problem domain; knowledge of the domain is important to understand whether it is applicable or will likely produce poor results. While hashing features may produce a smaller model, it will be one built from odd combinations of real-world features, and so will be harder to interpret.
An additional benefit of feature hashing is that the unknown and unbounded vocabularies typical of word-like variables aren't a problem.
NEW QUESTION 73
You have collected the 100's of parameters about the 1000's of websites e.g. daily hits, average time on the websites, number of unique visitors, number of returning visitors etc. Now you have find the most important parameters which can best describe a website, so which of the following technique you will use
- A. Linear Regression
- B. Logistic Regression
- C. PCA (Principal component analysis)
- D. Clustering
Answer: C
Explanation:
Explanation
Principal component analysis . or PCA, is a technique for taking a dataset that is in the form of a set of tuples representing points in a high-dimensional space and finding the dimensions along which the tuples line up best. The idea is to treat the set of tuples as a matrix M and find the eigenvectors for MMT or M T M . The matrix of these eigenvectors can be thought of as a rigid rotation in a high-dimensional space. When you apply this transformation to the original data, the axis corresponding to the principal eigenvector is the one along which the points are most "spread out,11 More precisely this axis is the one along which the variance of the data is maximized. Put another way, the points can best be viewed as lying along this axis, with small deviations from this axis.
NEW QUESTION 74
Select the correct algorithm of unsupervised algorithm
- A. Support Vector Machines
- B. K-Nearest Neighbors
- C. Naive Bayes
- D. K-Means
Answer: B
Explanation:
Explanation
Sup Supervised learning tasks
Classification Regression
k-Nearest Neighbors Linear
Naive Bayes Locally weighted linear
Support vector machines Ridge
Decision trees Lasso
Unsupervised learning tasks Clustering Density estimation k-Means Expectation maximization DBSCAN Parzen window
NEW QUESTION 75
A website is opened 3 times by a user. What is the probability of he clicks 2 times the advertisement, is best calculated by
- A. Poisson
- B. Normal
- C. Any of the above
- D. Binomial
Answer: D
Explanation:
Explanation
In a binomial distribution, only 2 parameters, namely n and p, are needed to determine the probability. Where p is the probability of success and q is the probability of failure in a binomial trial, then the expected number of successes in n trials.
This is a binomial distribution because there are only 2 possible outcomes (we get a 5 or we don't).
NEW QUESTION 76
What is the probability that the total of two dice will be greater than 8, given that the first die is a 6?
- A. 1/6
- B. 2/3
- C. 1/3
- D. 2/6
Answer: B
NEW QUESTION 77
Select the correct statement which applies to logistic regression
- A. Works with Numeric values
- B. All 1, 2 and 3 are correct
- C. Only 1 and 3 are correct
- D. May have low accuracy
- E. Computationally inexpensive, easy to implement knowledge representation easy to interpret
Answer: B
Explanation:
Explanation
Depending on the size of the data you are uploading, Amazon S3 offers the following options:
Logistic regression
Pros: Computationally inexpensive, easy to implement knowledge representation easy to interpret Cons: Prone to underfitting, may have low accuracy Works with: Numeric values^ nominal values
NEW QUESTION 78
Which method is used to solve for coefficients bO, b1, ... bn in your linear regression model:
- A. Integer programming
- B. Ordinary Least squares
- C. Apriori Algorithm
- D. Ridge and Lasso
Answer: B
Explanation:
Explanation : RY = b0 + b1x1+b2x2+ .... +bnxn
In the linear model, the bi's represent the unknown p parameters. The estimates for these unknown parameters are chosen so that, on average, the model provides a reasonable estimate of a person's income based on age and education. In other words, the fitted model should minimize the overall error between the linear model and the actual observations. Ordinary Least Squares (OLS) is a common technique to estimate the parameters
NEW QUESTION 79
Which of the following is a correct example of the target variable in regression (supervised learning)?
- A. Reptile, fish, mammal, amphibian, plant, fungi
- B. Nominal values like true, false
- C. Infinite number of numeric values, such as 0.100, 42.001, 1000.743..
- D. All of the above
Answer: D
Explanation:
Explanation
We address two cases of the target variable. The first case occurs when the target variable can take only nominal values: true or false; reptile, fish: mammal, amphibian, plant, fungi. The second case of classification occurs when the target variable can take an infinite number of numeric values, such as 0.100, 42.001,
1000.743, .... This case is called regression.
NEW QUESTION 80
You are asked to create a model to predict the total number of monthly subscribers for a specific magazine.
You are provided with 1 year's worth of subscription and payment data, user demographic data, and 10 years worth of content of the magazine (articles and pictures). Which algorithm is the most appropriate for building a predictive model for subscribers?
- A. Logistic regression
- B. TF-IDF
- C. Linear regression
- D. Decision trees
Answer: C
Explanation:
Explanation : A data model explicitly describes a relationship between predictor and response variables.
Linear regression fits a data model that is linear in the model coefficients. The most common type of linear regression is a least-squares fit, which can fit both lines and polynomials, among other linear models.
Before you model the relationship between pairs of quantities, it is a good idea to perform correlation analysis to establish if a linear relationship exists between these quantities. Be aware that variables can have nonlinear relationships, which correlation analysis cannot detect. For more information, see Linear Correlation.
If you need to fit data with a nonlinear model, transform the variables to make the relationship linear.
Alternatively try to fit a nonlinear function directly using either the Statistics and Machine Learning Toolbox nlinfit function, the Optimization Toolbox Isqcurvefit function, or by applying functions in the Curve Fitting Toolbox.
79
NEW QUESTION 81
In which of the scenario you can use the regression to predict the values
- A. Probability of the celebrity divorce
- B. Mobile companies can use it to forecast manufacturing defects
- C. Samsung can use it for mobile sales forecast
- D. Only 1 and 2
- E. All 1 ,2 and 3
Answer: E
Explanation:
Explanation
Regression is a tool which Companies may use this for things such as sales forecasts or forecasting manufacturing defects. Another creative example is predicting the probability of celebrity divorce.
NEW QUESTION 82
You are creating a regression model with the input income, education and current debt of a customer, what could be the possible output from this model.
- A. Customer fit as acceptable or average category
- B. expressed as a percent, that the customer will default on a loan
- C. 2 and 3 are correct
- D. Customer fit as a good
- E. 1 and 3 are correct
Answer: B
Explanation:
Explanation
Regression is the process of using several inputs to produce one or more outputs. For example The input might be the income, education and current debt of a customer The output might be the probability, expressed as a percent that the customer will default on a loan. Contrast this to classification where the output is not a number, but a class.
NEW QUESTION 83
Question-13. Which of the following is not the Classification algorithm?
- A. Neural Network
- B. Logistic Regression
- C. Support Vector Machine
- D. Hidden Markov Models
- E. None of the above
Answer: E
Explanation:
Explanation
Logistic regression
Logistic regression is a model used for prediction of the probability of occurrence of an event. It makes use of several predictor variables that may be either numerical or categories.
Support Vector Machines
As with naive Bayes, Support Vector Machines (or SVMs) can be used to solve the task of assigning objects to classes. But the way this task is solved is completely different to the setting in naive Bayes.
Neural Network
Neural Networks are a means for classifying multidimensional objects.
Hidden Markov Models
Hidden Markov Models are used in multiple areas of machine learning, such as speech recognition, handwritten letter recognition, or natural language processing.
NEW QUESTION 84
......
New Databricks-Certified-Professional-Data-Scientist Dumps - Real Databricks Exam Questions: https://examsboost.dumpstorrent.com/Databricks-Certified-Professional-Data-Scientist-exam-prep.html